さっそく、文章検索等では古典的な手法であるTF-IDFを勉強してみることにしました。TF-IDFは、文章に含まれる単語の発生頻度(TF)と、比較対象全体の文章での単語のレア度(IDF)を乗じて、数値化できるようにしたものだそうです。文章の意味は機械は理解しないけれども、TF-IDFを使って多次元でベクトル化(後述)した膨大な学習データから近いものを選ぶというときに、それなりの精度が出せるという特徴があるとのことです。
学習データの例としては、以下のようなものを想定しています。質問と回答の1:1のデータを、1万点ほど集めるのが目標です。一人でデータを作ってるので、まだまだ不足してます。ユーザーの皆様からの、学習データ提供を募っています。

LokSoundはアナログで動かせますか?
この文章を、まずは形態素解析に掛けて、”分かち書き”します。使ったのは、TinySegmenterという画期的に小さな形態素解析エンジンです。相当に有名なエンジンです。
LokSound|は|アナログ|で|動かせ|ますか|?
分かち書きすると、文章が単語ごとに分割されます。TinySegmenterは、精度はベストではないですが、処理スピードや軽量な点で、バランスが取れているので、このまま使っていこうと思ってます。
次に、この分かち書きしたデータから、Stop Words に該当する助詞・品詞を除去していきます。これは、”意味を成さない言葉”を排除して、学習データを軽量化するために使用します。”は”とか”で”とかは、単独では何も意味を成さないですし、TF-IDFでは、言葉のつながりの意味は無視するアルゴリズムなので、効率化のためにStop Words を使用して文章のスリム化を行います。
Stop Words には以下を選定しました。
だ|き|する|え|み|た|ど|ます|?|!|。|、|,|.|・|/|ある|あり|ん|ませ|が|の|を|に|へ|と|より|から|で|や|ば|と|ても|でも|から|ので|が|けれど|けれども|のに|て|で|し|ながら|たり|だり|なり|つつ|ものの|ところで|は|も|こそ|さえ|でも|だって|しか|ばかり|など|まで|だけ|ほど|きり|ぎり|くらい|ぐらい|なり|やら|か|だの|なんて|ずつ|とか|すら|な|なあ|や|よ|わ|こと|な|ぞ|ぜ|とも|か|の|ね|ねえ|さ|かしら|もの|ものか
StopWordに引っかかる分かち書きした単語は、完全一致で除去するように処理します。そうすると先ほどの言葉は以下のように変換されました。
LokSound,アナログ,動かせ,ますか
次にTFをこの文章に掛けます。単語の数は4つで、全て1つずつしか含まれないので以下のようになります。
LokSound :0.25
アナログ :0.25
動かせ :0.25
ますか :0.25
IDFは、全文章に探索を掛けます。以下のように、たくさんのDCCやオープンサウンドデータに関するFAQの質問文を用意して、IDFを求めます。
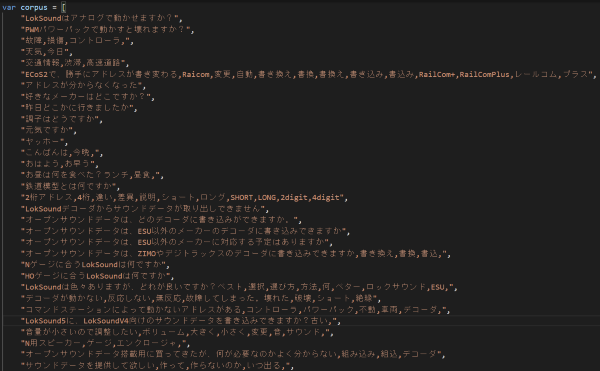
計算した結果は以下の通りです。
LokSound : 2.637608789400797
アナログ : 3.8903717578961645
動かせ : 3.8903717578961645
ますか : 2.504077396776274
“LokSound”というキーワードのIDFは2.63となり、実はこの値は、”オープンサウンドデータ”と同じくらいになってます。つまり、よく出てくる言葉で、あまり重要度は高くないという数値結果になってます。とはいえ、60個程度の文章では、レア度はそれほど大きく変化はありません・・・。
最後にTF-IDFという言葉通り、TFとIDFの数値を掛けます。
LokSound : 2.637608789400797*0.25=0.659402197
アナログ : 3.8903717578961645*0.25=0.972592939
動かせ : 3.8903717578961645*0.25=0.972592939
ますか : 2.504077396776274*0.25=0.626019349
という事で、TF-IDFのアルゴリズムは実装できたので、次は、文章のベクトル化と、文章同士の近さ(類似度)を数値で表現する、コサイン類似度を実装して、評価していきたいと思います。
ベクトル化は、2つの文章の単語を、それぞれTF-IDFして求めるものです。そのあと、cosΘが外積と内積で求まることを利用して、1に近いほど類似していると判定する仕組みです。
とりあえず、35文章に「LokSoundはDCC用ですが、アナログの模型にも使用できますか?」という文章を比較させたところ、以下のような類似度の数値が出ました。1.0に近い数値ほど、似ていると機械が判定していることになります。類似度をすべて計算し、ベスト4の文章を並べました。
“オープンサウンドデータはアナログで動かせますか?LokSound,ロックサウンド,ESU”
→類似度: 0.29020261213640164“LokSoundはアナログで動かせますか?”
→類似度: 0.2723745578371107“鉄道模型とは何ですか”
→類似度: 0.20578152752675852“オープンサウンドデータは、ESU以外のメーカーのデコーダに書き込みできますか”
→類似度: 0.1706526228267105
この技術は、DCCやデジタル鉄道模型の自動サポートシステムに使用する予定です。つきましては、DCCに知見を持つ皆様からの、学習データ(質問と、その解答)の提供を心よりお待ちします。